

Really simple OCR implementation
There are times when we could really use some numbers from a UI to improve our bot decision-making process. However, when reading game state using only image analysis it is a bit tough. This is where OCR comes in. It stands for optical character recognition and describes techniques used to convert an image to text. These usually involve usage of neural networks but that is not the approach we will take today. I will show you really simple take on this problem, using only image search. It is fast and reliable; however, I recommend using it only for short (one line) analysis, especially for numbers.
Input
Here is sample image containing mana bubble. Our goal is to read current and maximum mana.
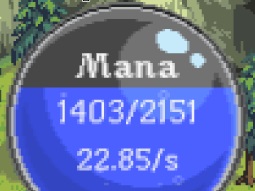
Before I decided to implement my own OCR I tested an open source solution which took way too long to analyze and failed completely. I manually corrected background to be black before testing to make OCR task easier. I suppose the reason is that characters are only about 9 pixels high and blurry. It all depends on how particular OCR was implemented and I didn't bother to investigate that.
First, we need to prepare our input. We will take this fragment of game's window screenshot, making sure it contains only one line of text.

Analysis
Our algorithm consists of series of image searches using every character that we want to recognize. Since we want to ignore background color, image search must support specifying transparency color. Any pixel with color matching transparency key will be ignored (treated as matching). Other pixels' colors must fall within specified tolerance. As you can see this is brute force approach. It takes some preparation (we need a pattern for every recognizable symbol) but I had it running in about an hour (including collecting samples and tweaking). Performance wise I was able to analyze input image in ~30ms.
Here is image being a combination of all symbols patterns that I used (black is transparency color and I had to use gray background so you can see actual patterns):

Here is how I configure OCR:
public class NaiveOCR
{
public class Symbol
{
public Symbol(Bitmap image, string character, bool canBeFirst, int toleranceOverride = -1)
{
m_image = image;
m_character = character;
m_canBeFirst = canBeFirst;
m_toleranceOverride = toleranceOverride;
}
public Bitmap m_image;
public bool m_canBeFirst;
public string m_character;
public int m_toleranceOverride;
}
//...
}
List<NaiveOCR.Symbol> symbols = new List<NaiveOCR.Symbol>();
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/0.bmp"), "0", false, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/2.bmp"), "2", true, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/4.bmp"), "4", true, 115));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/7.bmp"), "7", true, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/8.bmp"), "8", true, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/6.bmp"), "6", true, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/9.bmp"), "9", true, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/5.bmp"), "5", true, 135));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/3.bmp"), "3", true, 100));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/1.bmp"), "1", true, 90));
symbols.Add(new NaiveOCR.Symbol(new Bitmap("img/ocr/mana/slash.bmp"), "/", false, 135));
NaiveOCR ocr = new NaiveOCR(symbols);
When looking for a symbol we look for the first match, thus order of symbols matters. This is especially important for characters that could be recognized as a subpart of other symbols. "1" is a great example here since it could occasionally be recognized as a part of "0" or "4", depending on how blurry these were rendered. Keep in mind that any given symbol may look slightly different every time.

A pattern must contain pixels representing symbol characteristics. Since in this example, we are recognizing white characters tolerance describes how white pixel has to be in order to be recognized as part of a pattern. Parts of some symbols, like "3" are never rendered in "full" white, thus we may need to "grayify" them a little bit in pattern to improve matching accuracy.
Additional optimization is ignoring some characters when looking for the first match. Identifying the first symbol is the most expensive part of our algorithm since we have to go through all symbols and find the one that is found at the smallest X coordinate. Here is the algorithm implementation:
public class NaiveOCR
{
//...
public bool Recognize(Bitmap img, out string output, int tolerance = 115)
{
output = "";
int x = 0;
int y = 0;
bool first = true;
bool found_anything = false;
while (true)
{
if (!FindSymbol(img, first, x, y, ref x, ref y, ref output, tolerance))
break;
found_anything = true;
first = false;
}
return found_anything;
}
private bool FindSymbol(Bitmap img, bool first, int left, int top, ref int x, ref int y, ref string output, int tolerance)
{
int min_x = img.Width;
int min_y = 0;
Symbol min_symbol = null;
foreach (Symbol s in m_symbols)
{
if (first && !s.m_canBeFirst)
continue;
if (AutoIt.ImageSearchArea(s.m_image, 0, left, top, Math.Min(img.Width, min_x), img.Height, ref x, ref y, s.m_toleranceOverride > 0 ? s.m_toleranceOverride : tolerance, IGNORE_COLOR, img) && x < min_x)
{
min_x = x;
min_y = y;
min_symbol = s;
}
}
if (min_symbol != null)
{
x = min_x + min_symbol.m_image.Width;
y = min_y - 2;
output += min_symbol.m_character;
return true;
}
return false;
}
//...
}
That's it. The algorithm is really simple. Find symbol located at minimum X coordinate, narrow search region, and look again.
Testing/debugging
I used following code to check if OCR works properly.
string output = "";
ocr.Recognize(ocrImg, out output);
string manaStr = output.Split('/')[0];
int mana = manaStr.Length > 0 ? int.Parse(manaStr) : 0;
ocrImg.Save("ocr_dbg/" + Tools.DateAsString() + "_" + Tools.TimeAsString() + "__" + manaStr.Replace("/", "-") + ".bmp");
It saves input image and names the file with recognized text. I can then quickly go through these files and check if recognition was right. In case of failure, I can use saved image to feed it into recognition system and debug what happened.
This is it, full source of NaiveOCR class along with simple test class and required AutoIt/ImageSearch dlls are available for everyone on https://www.patreon.com/bottersgonnabot. Enjoy!